Introduction
These notes will serve as the main companion to the slides and lectures for the Practical Data Science course. For the most part, these will be technical notes, describing the algorithms, libraries, and code relevant for the lecture (plus code to generate all the figures from the slides), but for this introductory lecture, they are going to be a more high-level description of the philosophy and nature of the course. Along with the lectures and slides, these are the only “required” material for the course, but as fair warning, you will need to consult outside resources like API documentation for the various programming assignments. Wherever possible, I’ll try to give pointers to additional resources on the material, but just like real data science work, there will be cases where you’ll need to seek this out yourself.
One additional meta-comment worth mentioning is that these notes are intentionally written in an informal tone. In general, I will use the first person “I” to indicate some opinion or action that I (Zico Kolter, the instructor of the course) am putting forward. I’ll similarly try to use the term “we” to indicate the group of all of us participating in the course (instructor and students together), and “you” to indicate students in the course specifically. It is not a perfect system, but I find it generally helps to convey the intention that I have when writing these notes. The informal tone also frankly helps to convey the fact that these are notes to the course and not meant to be a substitute for a formal text if one wants to delve deeply into any of these specific areas.
What is data science?
The start of any good data science course should probably begin with a definition of the term “data science”, or at least what this term means in the context of this particular course (because different people and disciplines use the term quite differently). Despite the fact that people have been “doing” data science for a long time in some form or another, the term itself is relatively new, and different fields have attempted to co-opt the term in different ways (none of which I necessarily disagree with, but it does make for a hard time finding a single definition). For the most part, I’m going to avoid a strict definition throughout the course, instead following a more pragmatic notion of “data science is whatever data scientists do”, or maybe more correctly “data science are those skills required in data science job postings”.
But if we do want a concise definition that fits reasonably with the themes of this course, the following seems to be reasonable:
Data science is the application of computational and statistical techniques to address or gain insight into some problem in the real world.
The key phrases of importance here are “computational” (data science typically involves some sort of algorithmic methods written in code), “statistical” (statistical inference lets us build the predictions that we make), and “real world” (we are talking about deriving insight not into some artificial process, but into some “truth” in the real world). After these main points, I have little problem referring to anything in this domains as “data science”, and typically will not belabor the point.
Another way of looking at it, in some sense, is that data science is simply the union of the various techniques that are required to accomplish the above. That is, something like:
Data science = statistics + data collection + data preprocessing + machine learning + visualization + business insights + scientific hypotheses + big data + (etc)
This definition is also useful, mainly because it emphasizes that all these areas are crucial to obtaining the goals of data science, and thus are fair ground for inclusion in a data science course. In fact, in some sense data science is best defined in terms of what it is not, namely, that is it not (just) any one of these subjects above.
What is data science not?
Now that we have defined data science, it is worth emphasizing why we need such a broad definition, and don’t want to simply reduce data science to one of it’s constituent parts. And although several fields often do reduce data science to simply “another name” for that field, I don’t think that this captures the full scope of the field.
Data science is not (just) machine learning
As a first example, and one which I personally see very frequently (likely because machine learning is my own area of research focus, so I naturally discuss it more than most areas), is the notion that data science is merely a new term for machine learning. This notion is evident, for instance, the tagline of companies like Kaggle, which bills itself as “the home of data science and machine learning.” I don’t mean to pick on Kaggle here, because I am actually a huge fan of their company what they do (for those who don’t know, Kaggle runs machine learning contests, where participants download a data set, upload predictions for some unseen portion of the dataset, and try to optimize various performance metrics, usually with some prize for the top entries). Kaggle is a wonderful resource, but the competitions are decidedly not data science. Making good machine learning based predictions can be an important part of data science, but the truly hard elements of data science involve also involve collecting the data to begin with, defining the problem you’re trying to solve (and frequently, re-defining it many times based upon improved understanding of the problem over time), and then interpreting and understanding the results, and knowing what actions to take based upon this. Kaggle contests decidedly do not address almost any of these points. And to be fair, the people at Kaggle are well aware of this fact, and have even been moving toward something that is much more along the lines of “complete” data science with their Datasets and Kernels pages (which are much more in line with this course’s definition of data science), but their flagship machine learning
Furthermore, machine learning as a field is typically concerned primarily about the development of new algorithms. Deep learning methods, for instance (typically defined as methods based upon multi-layer neural networks, though honestly the right definition of “deep learning” is as hard as the right definition of “data science”, more on that in a later lecture) have come to dominate much recent work in machine learning, and the focus here is often on advanced (and typically quite complex) algorithms that can squeeze out improved performance on extremely challenging tasks. The reality is that for many data science problems, simple machine learning algorithms suffice to attain sufficiently good performance (by whatever metric you want to define performance, but I simply mean that they effectively solve the problem). I’m partial to drawing this picture for people when they ask about how data science compares to machine learning research:

A (rhetorical) breakdown of the universe of machine learning problems
The numbers here are all just examples (specifically the solvable/unsolvable ratio), but the point it gets at is important. There are many data science problems one would like to be able to solve, but in a large number of these cases, there is simply no way to solve the problem given the available data. For the set of problems that are solvable with some kind of machine learning, the vast majority will be solvable at least to a level of sufficient performance, using relatively simple models. The 5% of remaining problems is an important one, because they often consist of the most “interesting” problems from a research standpoint (think problems like speech recognition, natural language understanding, computer vision), but they are often not indicative of the types of problems one encounters in “most” data science applications.
Data science is not (just) statistics
So if data science is not machine learning, perhaps simple Statistics (that is, the discipline of Statistics) is a better fit? After all, “analyzing data computationally” … “to understand phenomena in the real world”? This sounds an awful lot like statistics. And I think the fit here is frankly much better than for the standard definition of machine learning. Indeed, the Statistics department at CMU just renamed itself to “Statistics and Data Science”.
There are, however, two primary distinctions that are worth making about between data science and Statistics as it is commonly practiced in an academic setting. The first is that historically, the academic field of statistics has tended more towards the theoretical aspects of data analysis than the practical aspects. David Donoho has an excellent article on this subject, 50 years of data science, which doubles as an alternative view of data science from a more statistics-centric standpoint, which does an excellent job of covering the distinctions between traditional statistics. Second, from a historical context, data science has evolved from computer science as much as it has from statistics: topics like data scraping, and data processing more generally, are core to data science, typically are steeped more in the historical context of computer science, and are unlikely to appear in many statistics courses.
The last difference, of course, is that statisticians use R, while data scientists use Python. This is non-negotiable. (Since my sarcasm may not come across correctly in written form, yes, I’m saying this tongue-in-cheek, but there absolutely is a grain of truth here: R, or more specifically, the vast set of libraries that have been developed for R, are far superior for running advanced statistical algorithms; but Python is a much nicer language for collecting and processing data, especially if you consider the set of external libraries it supports).
Data science is not (just) big data
Lastly, there is still a contingent that equates data science with the rise of big data (again we’re likely dealing with a term that needs its own set of notes defining it, for the purposes of these notes, let’s assume that big data just refers to data that can’t easily fit in memory on a single machine). And while it’s absolutely true that some data science work really does use vast amounts of data to build models or gain insights, this is frankly the exception rather than the rule. Most data science can work just fine using the (right set of) data that still fits into memory on a single machine. It’s useful to know the techniques needed to address big data challenges, but don’t create more work for yourself if you don’t have to.
Some data science examples
Often times the best way to demonstrate data science is by example. The following are three brief pointers to data science work, where the main point to convey here is the diversity of what can constitute a data science project. They can range from “simple” visualization, where the main “result” of the work is ultimately a figure or method of visualizing data, to complex predictive procedures that require a great deal of advanced algorithms.
Gendered verbs in professor reviews
One excellent example of data science that I saw recently was developed by Ben Schmidt, a professor of history at Northeastern University. It is an interactive chart, available here: http://benschmidt.org/profGender, with figures that look like this:
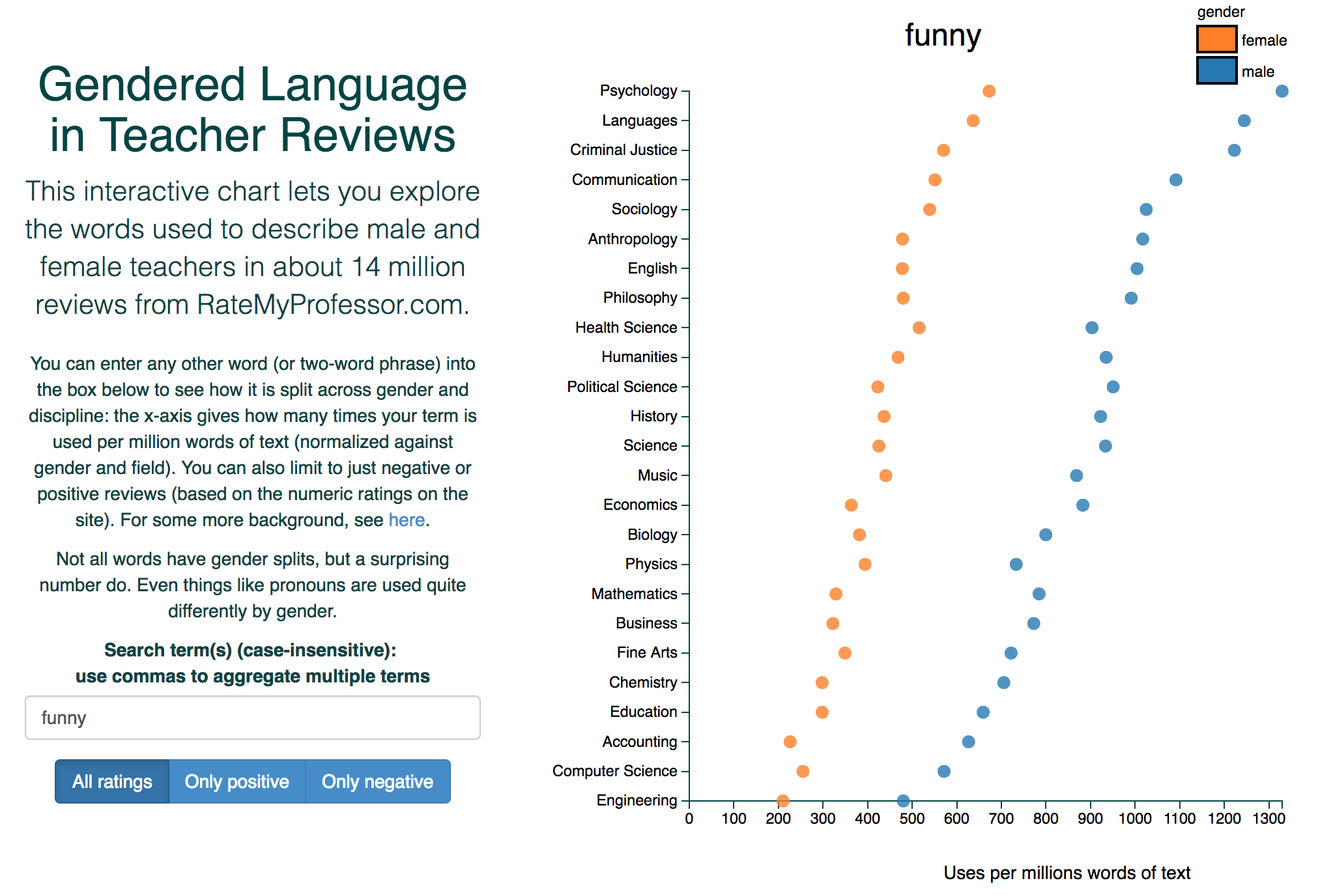
Gendered language in professor reviews. Image source: http://benschmidt.org/profGender
The work collects 14 million reviews from RateMyProfessor.com, and counts the number of occurrence of different terms, per million words, for reviews of male and female professors (no information about the gender of the student reviewers is available, as the site offers anonymous reviews). It then plots these occurrences for professors in across different disciplines, sorted by the number of occurrences across all reviews.
Part of what I love about this example is that it is so “simple” from a data science perspective: there is no machine learning, not even any basic statistics, no predictions, really even no inferences about what this “means” regarding the true nature of reviews for gender (in the comments on the page, Ben Schmidt explicitly notes that this is not meant to replace any of the numerous studies showing such differences in a much more controlled setting). But the beauty of this interactive figure really does come from the simplicity. There is a famous quote by John Tukey (a reknown statistician), which seems to be quoted in the first lecture of almost every data science course I’ve seen, so I better continue the practice:
The greatest value of a picture is when it forces us to notice what we never expected to see. -John Tukey
Frankly unlike many of the more controlled studies on this same topic, it is extremely easy to understand the data being shown in the figure, and the conclusions are left to the observer. Despite using only the “material” that we cover up to about the third week of class, if anyone had submitted something like this as their final project, it would have absolutely received a top grade (though you’d need to build on something like this in a substantial way at this point, of course, if you want to work on something similar for your project).
FiveThirtyEight
Considering a slightly more complex example of data science, one of the most publicly visible instances of data science has been websites like FiveThirtyEight. FiveThirtyEight, at this point, has become a general web page for data-driven analysis in a lot of different areas, but its original and still most famous products are its political election forecasts. Here is the map that FiveThirtyEight produced prior to the presidential election day in 2016:
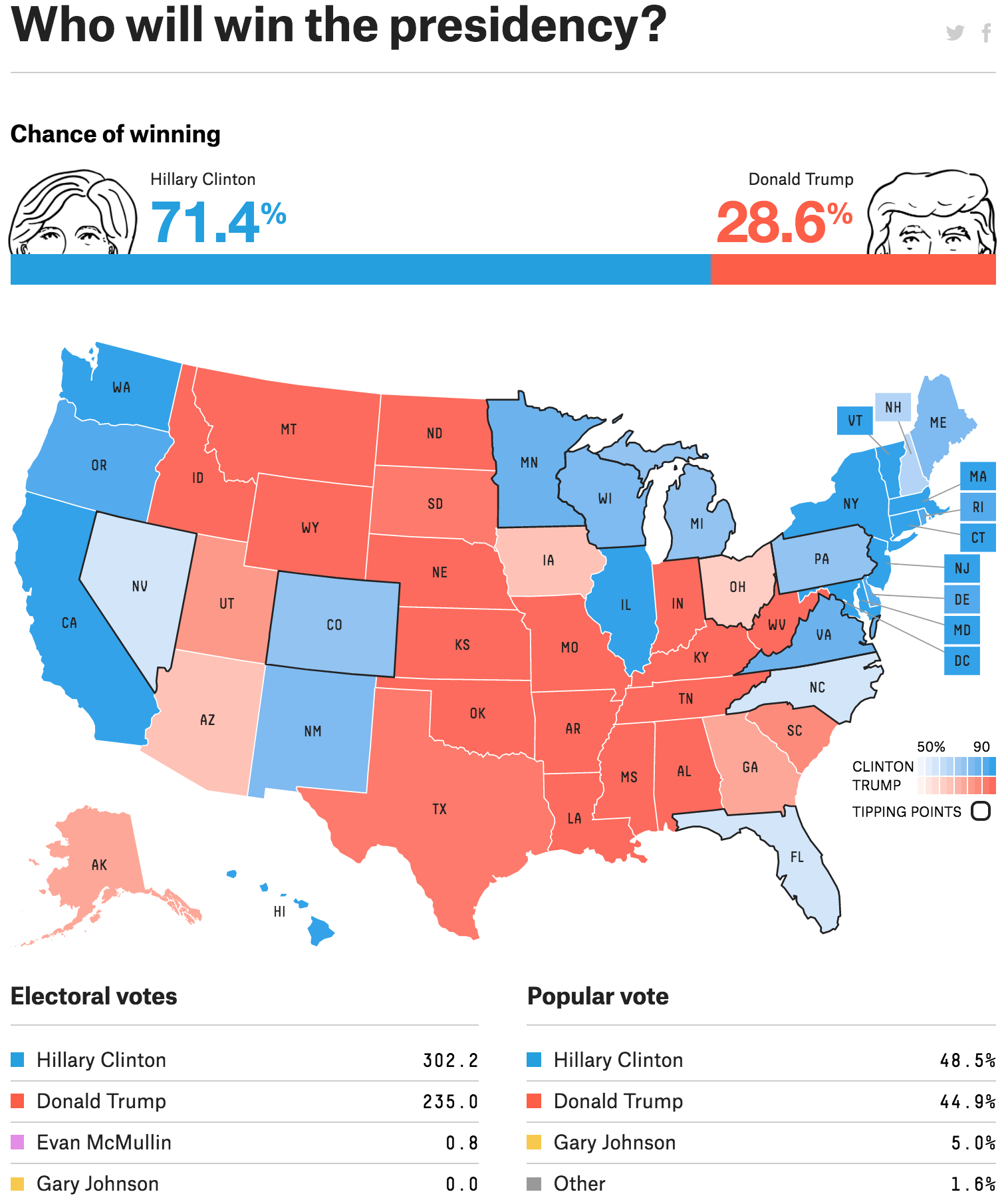
Final 2016 election predictions at FiveThirtyEight. Image source: https://projects.fivethirtyeight.com/2016-election-forecast/
There are a couple of points worth mentioning here. First of all, the analysis here goes beyond what is done in the previous example, both in terms of the nature of this analysis (it is making a prediction about the future, not just visualizing a fixed data set) and in terms of the methodology. FiveThirtyEight doesn’t publish their model in full detail, but from text descriptions we know that it mainly averages polling data from publicly available polls, but also weights these polls by various accuracy measures, and does include some amount of “generic” features that also help to predict the election (though it’s unclear to what extent such features are included so close to the actual election).
The second point, which is slightly tangential, is that the public narrative around the election forecasts in 2016 is that the data scientists got it “wrong”. Virtually every forecaster predicted that Hilary Clinton would win the election, while of course Donald Trump won; this contrasts with 2012 where the data scientists were hailed as “right” because FiveThirtyEight happened to have the correct predictions for each state; but even saying “correct” here is not very precise, they simply had greater than 50% probability for the true winner of each state (and in some cases like Florida, barely greater than 50% probability). And it’s true that in aggregate, virtually every prediction forecaster had Hilary Clinton winning the election. But what’s also true, and which FiveThirtyEight tried endlessly to explain (to no apparent avail), is that because all the forecasters were using the name data (namely, aggregation of different public polling results), it wasn’t as if there were many different forecasts that all got it wrong: these forecasts were all using same underlying data, and so were really just slightly different takes on the same prediction. The second thing that FiveThirtyEight tried extremely hard to emphasize is that the errors in polling (and hence the errors in the forecasts) were likely to be highly correlated across states. If the Pennsylvania polls were off, the Michigan polls were likely to be off too. This is why Donald Trump actually had a relatively high probability of winning under their model (compared to most forecasts), but in the end it didn’t matter much to the public narrative. Despite assigning a (seemingly reasonable, even in hindsight), 28% change to Donald Trump winning the election, FiveThirtyEight and the other forecasters were “wrong”; it’s an important lesson to keep in mind regarding how we disseminate and speak about probabilities.
Poverty mapping
We’ll end with a third example that goes beyond the first two fairly substantially in terms of using fairly complex machine learning algorithms to derive insights into a real-world setting. This work appears in the paper: “Targeting Direct Cash Transfers to the Extremely Poor” by Brian Abelson, Kush R. Varshney, and Joy Sun. The idea of this paper is that the authors want to understand what communities in Kenya and Uganda would benefit most from charitable donations. They found (in previous studies) that one of the highest indicators of relative wealth in these countries is the number of people who have metal roofs instead of thatched roofs. The goal of this particular work, then, was to use computer vision techniques applied to satellite imagery to automatically estimate the number of metal and thatched roofs across various region. They would take images such as this:

Aerial images of buildings in the poverty mapping study. Source: Abelson et al.
And use machine learning to detect the location and type of different roofs in the image (based upon a training set of manually labeled images). They would then use this information to predict a “poverty heat map” of large regions of the countries (much larger than would be feasible to annotate manually), to produce maps like this:
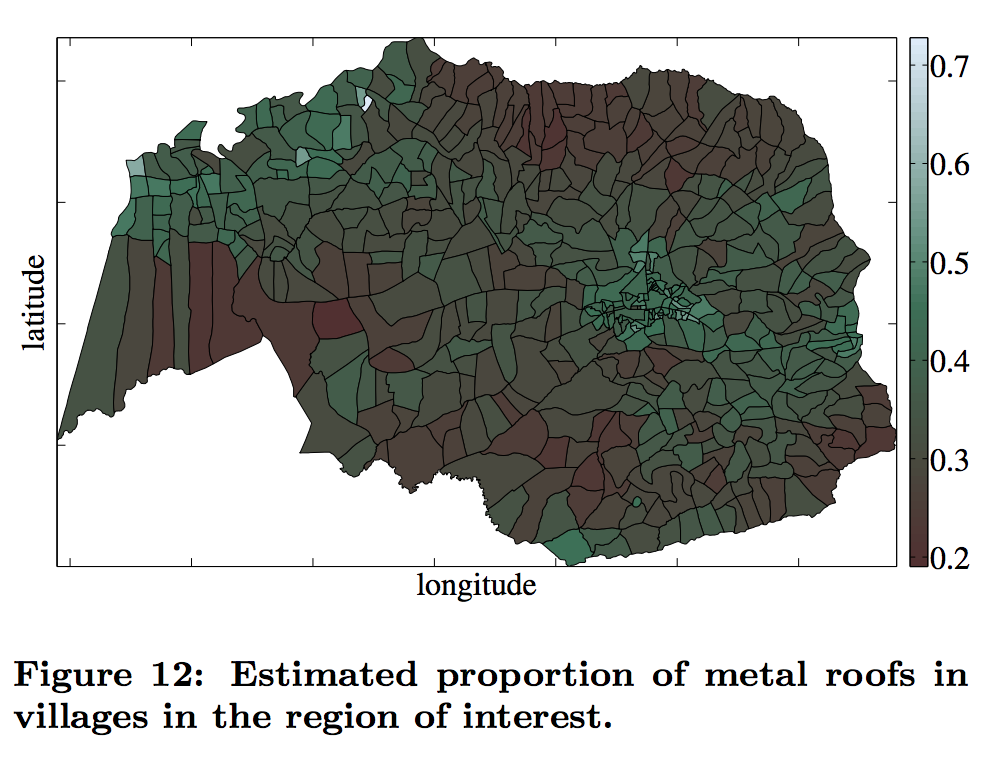
Heatmap of percentage of metal roofs over area of interest. Source: Abelson et al.
These images were then used by the charity to help target areas of particularly high poverty.
Applications such as this highlight that in many cases it really does pay off to use state of the art machine learning methods within data science applications: as computer vision techniques have improved due to advances in deep learning, methods for analyzing satellite imagery have improved dramatically. Stefano Ermon’s group at Stanford has been particularly active in this area, and has a number of papers on using advanced machine learning techniques (much more advanced that those in the above paper) to learn from satellite imagery. His group and others at Stanford have a recent paper in Science on using deep learning to map poverty in a much more generic manner than that described above: “Combining satellite imagery and machine learning to predict poverty” by Jean et al. As a whole I think this work represents one of the most compelling use cases of advanced machine learning within data science.
What is the Practical Data Science course about?
So with all this as context, what is this course, Practical Data Science, actually about? Put simply, the goal of this course is to expose students to the entire pipeline associated with data science projects. That is, the course will teach you the basics of everything you need to understand how to embark on data science projects: data processing and collection, data exploration and vizualization, machine learning methods, statistical analysis techniques, and (perhaps most importantly) techniques for debugging this pipeline when things do not work an hoped for. A reasonable figures that sums up the course would be the following:

The data science pipeline
Except in reality, this is virtually never a linear process: experience and insights at later stages feed back and change what we do at previous stages. So this is like a better figure:

A more accurate data science pipeline
Admittedly, one thing you will notice from the course schedule, though, is that all these topics are not treated equally in terms of the number of class lectures. Part of this is simply due to my own biases: I do, after all, work in machine learning, and thus have a decidedly larger focus on these topics, both because I believe these topics to be important, and because I am likely to teach them better. Data collection is hugely valuable, but I’m not sure how I would fill multiple lectures on web scraping, for instance.
But another rationale for this unequal breakdown is more pragmatic. I have worked extensively in data science both within academics and industry (in addition to being faculty at CMU I serve at the Chief Data Scientist for C3 IoT, a company in the Enterprise AI and Data Science space). And in my experience, for better or worse the vast majority of data science positions, at least in industry, and heavily geared towards machine learning techniques. Part of the impetus for this course came from the time I spent in industry, seeing people with a huge diversity of background skills apply for data science positions, and compiling a wish list of topics that I would have liked them to all be familiar with. Hopefully this will bode well for those of you taking the course that are also looking to explore industry data science positions moving forward.